


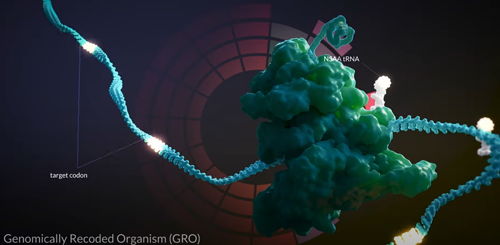
Figura 1 – Nos organismos genomicamente modificados os ribossomos podem sintetizar proteínas utilizando mais de 500 aminoácidos não canônicos! Durante bilhões de anos a natureza evoluiu de maneira espetacular criando as mais diferentes formas de vida contando com apenas 22 aminoácidos
Por: Prof. Roberto N. Onody*
Durante 3,5 bilhões de anos a vida na Terra evoluiu (de maneira extraordinária) baseada num código genético que opera com apenas 22 aminoácidos. Estes aminoácidos (chamados de canônicos ou padrões) fazem parte da composição química de milhões de proteínas, presentes em todos os organismos vivos que existem ou que existiram no nosso planeta.
Mas, tudo isso está prestes a mudar com o surgimento dos organismos genomicamente recodificados. Esses organismos têm o seu código genético expandido de forma a permitir que eles codifiquem novas proteínas utilizando os mais de 500 aminoácidos não canônicos conhecidos na natureza!
A expansão do alfabeto de aminoácidos permitirá a introdução de novas proteínas terapêuticas, novas drogas para imunoterapia, novas vacinas com a utilização de vírus atenuados genomicamente recodificados etc. Para desenvolver essa nova área – a biologia sintética, várias startups estão sendo criadas como a GRO Biosciences e a Pearl Bio.
Os organismos genomicamente recodificados (Figura 1) representam uma mudança importante no paradigma evolucionário que foi adotado pela natureza durante bilhões de anos. Para compreender melhor esse aspecto, faço antes uma breve revisão de alguns elementos e mecanismos biológicos envolvidos na síntese de proteínas.
Sobre as Proteínas
As proteínas são os tijolos fundamentais na construção e na manutenção da vida como a conhecemos. Em qualquer um dos três domínios da vida – Bacteria, Archea ou Eukarya, as proteínas estão sempre presentes e são essenciais.
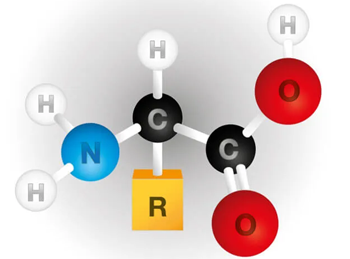
Figura 2 – A estrutura química de um aminoácido. Existem milhões de proteínas no mundo, mas, todas elas formadas a partir de somente 20 aminoácidos diferentes! Os aminoácidos se unem (quimicamente) através de uma reação de desidratação na qual o grupo carboxila de um dos aminoácidos se une ao grupo amino do outro, liberando uma molécula de água. Uma cadeia extensa assim formada chama-se polipeptídeo. Cadeias de polipeptídeos se unem entre si através de pontes de hidrogênio
As proteínas garantem a estrutura celular (citoesqueleto), catalisam reações metabólicas (enzimas), regulam atividades fisiológicas (hormônios) e são protagonistas na defesa do organismo (anticorpos). Proteínas malformadas ou com defeitos são responsáveis por várias doenças e podem até mesmo levar à morte do organismo.
Em uma única célula do corpo humano há cerca de 3 milhões de proteínas! Estima-se que existam cerca de 700.000 proteínas diferentes em todo o corpo humano e elas são produzidas num ritmo frenético – 120.000 proteínas por minuto!
Até outubro de 2023, havia um total de 227.064 proteínas (com suas estruturas tridimensionais completamente determinadas) catalogadas no PDB (Protein Data Bank).
Do ponto de vista químico, as proteínas são macromoléculas compostas por uma ou mais cadeias interligadas de aminoácidos. Os aminoácidos têm um carbono central (chamado de alfa) ligado a um grupo carboxila (O=C-OH), um grupo amino (NH2) e uma cadeia lateral ou grupo R (Figura 2).
Ao se ligarem entre si, os aminoácidos adquirem uma estrutura tridimensional muito particular e funcional, num processo conhecido por enovelamento da proteína (“protein folding”).
A insulina foi a primeira proteína que teve sua sequência de aminoácidos corretamente estabelecida em 1951 por Frederick Sanger (Figura 3). Com os avanços da técnica de cristalografia por difração de raios-x, foi possível se determinar, não somente a sequência de aminoácidos de uma proteína, mas, também toda a sua estrutura tridimensional.
A mioglobina foi a primeira proteína que teve sua estrutura tridimensional completamente determinada (em 1958, por John Kendrew). Na Figura 4, vemos um diagrama de fitas da mioglobina. O diagrama de fitas ou diagrama de Richardson (após Jane Richardson, biofísica norte americana que o concebeu na década de 1980) permite uma visualização rápida e simples da estrutura 3D de uma proteína. A fita é uma representação esquemática da hélice formada pelos carbonos centrais dos polipeptídeos. Um programa computacional bastante utilizado para montar esses diagramas é o MolScript.
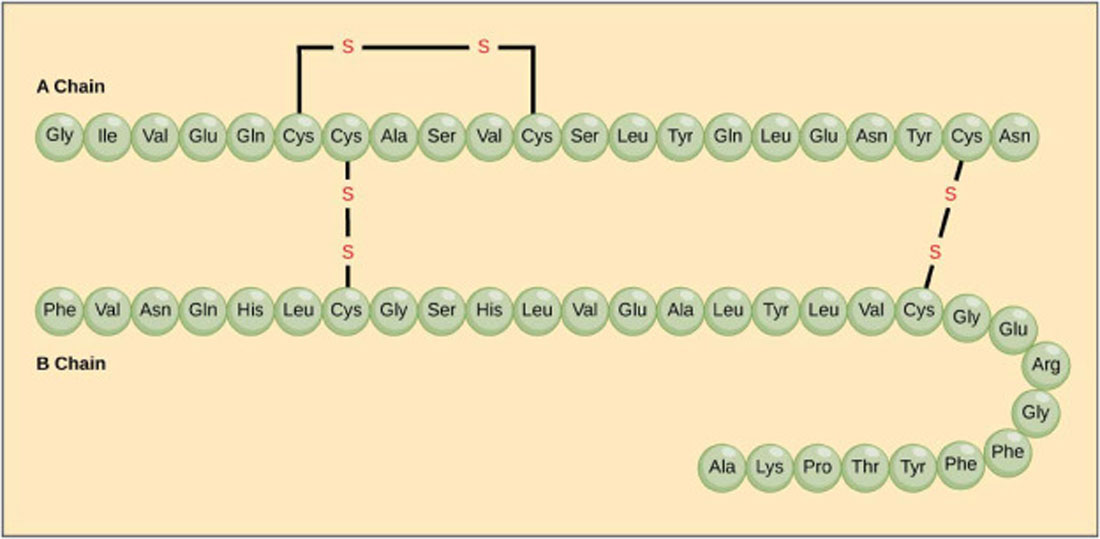
Figura 3 – A Insulina foi a primeira proteína que teve sua sequência de 51 aminoácidos corretamente estabelecida em 1951 por Frederick Sanger. Descoberta em 1921, a insulina é um hormônio sintetizado no pâncreas. É fundamental no metabolismo dos carboidratos, principalmente da glicose. Ela é formada por 2 cadeias de peptídeos (uma com 21 aminoácidos e a outra com 30 aminoácidos) que estão ligadas entre si por átomos de enxofre. Sua fórmula contém 788 átomos: C 257 H383 N65 O77 S6 (Crédito: domínio público)
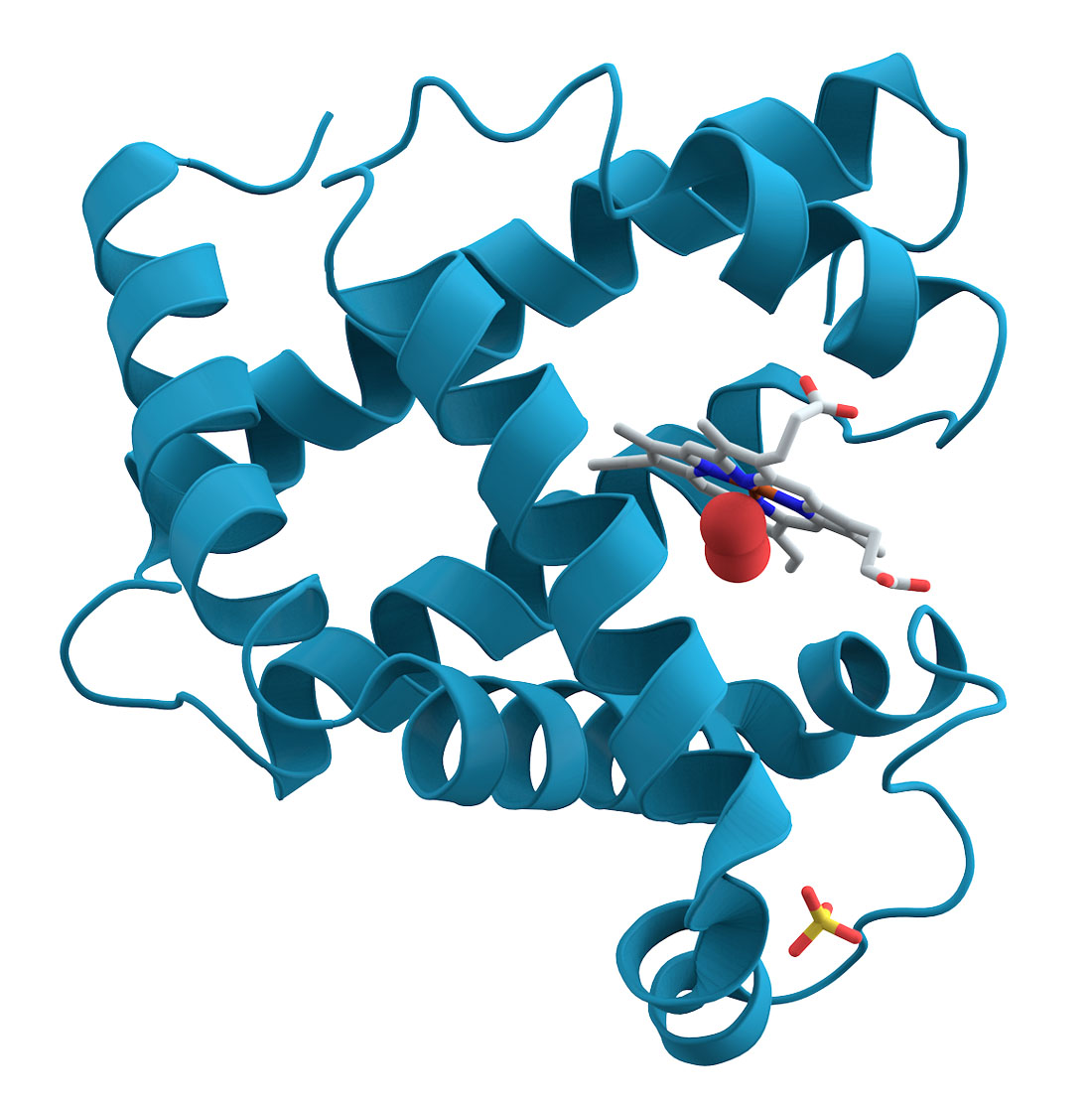
Figura 4 – A Mioglobina é uma proteína encontrada no tecido cardíaco e nos músculos do esqueleto de quase todos os vertebrados. Ela é composta por 153 aminoácidos. A mioglobina contém ferro e tem grande afinidade com o oxigênio. Em alta concentração, permite que o organismo possa segurar a respiração por um tempo maior. Não confundir com a hemoglobina, que é uma proteína presente nas hemácias (glóbulos vermelhos) e é responsável pelo transporte de oxigênio na corrente sanguínea (Crédito: domínio público)
A menor proteína conhecida é Trp-cage, encontrada na saliva do monstro-de-gila (um lagarto peçonhento encontrado na América do Norte, principalmente no México). A maior proteína conhecida é a Titin, encontrada nos músculos estriados dos vertebrados. Um corpo humano adulto contém 500g de Titin! Veja Figura 5.
Sobre os Aminoácidos
Cada órgão do corpo humano sintetiza seu próprio conjunto de proteínas necessárias para o seu pleno funcionamento. No entanto, para sintetizar uma determinada proteína, o órgão precisa ter disponíveis todos os aminoácidos que a constituem. As plantas sintetizam todos os tipos de aminoácidos, mas os animais não.
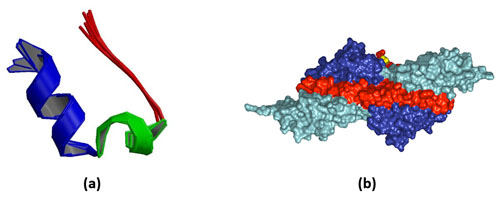
Figura 5 – (a) A proteína Trp-cage é a menor proteína conhecida. Ela contém somente 20 aminoácidos. (b) A proteína Titin é a maior proteína conhecida. Na sua versão humana, ela contém 34.350 aminoácidos (Crédito: domínio público)
Hoje, são conhecidos mais de 500 aminoácidos. De maneira surpreendente, todas as proteínas conhecidas (de todos os seres vivos) são sintetizadas a partir de apenas e tão somente 22 aminoácidos!
Para compor as proteínas que os seres humanos precisam, são necessários 21 tipos de aminoácidos. Conseguimos sintetizar apenas 12. Para obter os 9 aminoácidos restantes (justamente, os que são considerados essenciais) temos que nos alimentar das plantas ou de animais que delas se alimentaram. O prato brasileiro principal, feijão com arroz, contém todos os 9 aminoácidos essenciais.
Foi em 1806 que químicos franceses encontraram, no aspargo, o primeiro aminoácido – a asparagina (que não é um aminoácido essencial). Hoje sabemos que, na construção de qualquer proteína, o primeiro aminoácido a ser incorporado é a metionina (Figura 6).
Até 1974, acreditava-se que os aminoácidos presentes ou necessários ao corpo humano eram somente 20. Nesse ano, a bioquímica T. Stadtman descobriu o 21º. aminoácido – a selenocisteína. O 22º. aminoácido – a pirrolisina, foi descoberto por J. Krzycki e M. Chan em 2002 (Figura 7).
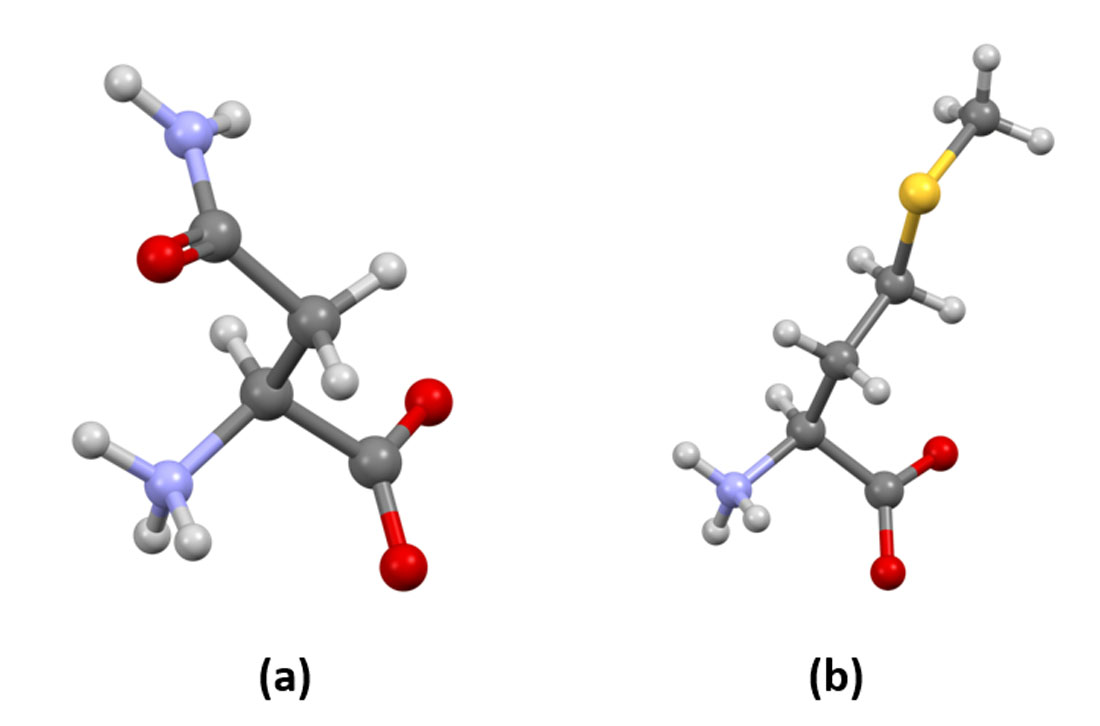
Figura 6 – (a) Asparagina – o primeiro aminoácido descoberto. Cores dos átomos: em cinza escuro (claro) Carbono (Hidrogênio); lilás – Nitrogênio; vermelho – Oxigênio (b) Metionina – um aminoácido essencial que é o primeiro aminoácido a ser incorporado na síntese de qualquer proteína. Cores dos átomos: em cinza escuro (claro) Carbono (Hidrogênio); lilás – Nitrogênio; vermelho – Oxigênio; amarelo – Enxofre (Crédito: domínio público)
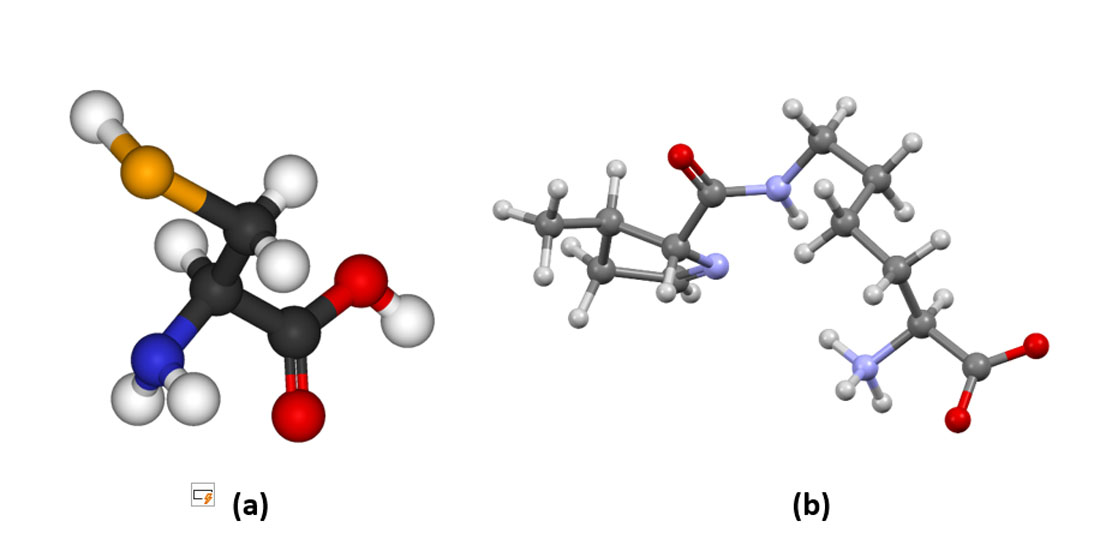
Figura 7 – (a) Selenocisteína – o 21º. aminoácido. É encontrado em enzimas e é bem parecida com a cisteína, com o átomo de enxofre substituído por selênio. Cores dos átomos: em cinza claro – Hidrogênio; preto – Carbono; vermelho – Oxigênio; azul – Nitrogênio; laranja – Selênio (b) Pirrolisina – o 22º. aminoácido. Não é encontrado no ser humano, mas está presente em microrganismos bactéria e archea. Cores dos átomos: em cinza escuro (claro) – Carbono (Hidrogênio); azul – Nitrogênio; vermelho – Oxigênio (Crédito: domínio público)
Sobre o código genético
Toda a informação biológica do ser humano está contida no seu DNA. O DNA (ácido desoxirribonucleico) é uma fita dupla formada por quatro nucleotídeos. Um nucleotídeo é composto por uma pentose (açúcar), um fosfato e uma das quatro bases nitrogenadas: adenina, timina, citosina e guanina. Na fita dupla, elas comparecem em pares: a adenina está sempre ligada com a timina e a citosina com a guanina. O DNA está compactado no interior do núcleo da célula. No caso do ser humano, ele está presente e contido em 23 pares de cromossomos. Se estendido o DNA de uma única célula teria cerca de 2 metros de comprimento (Figura 8).
Outro componente fundamental na síntese de proteínas é o RNA (ácido ribonucleico). Diferentemente do DNA, o RNA tem a forma de uma fita
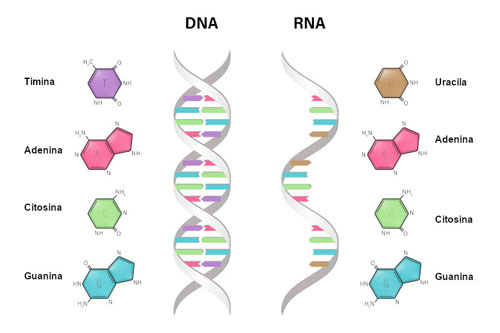
Figura 8 – O DNA é uma fita dupla de nucleotídeos contendo as bases nitrogenadas adenina (C5H5N5), citosina (C4H5N30), guanina (C5H5N5O) e timina (C5H6N2O2). O RNA é uma fita simples de nucleotídeos contendo as bases nitrogenadas adenina, citosina, guanina e uracila (C4H4N2O2)
simples composta por nucleotídeos que contêm uma das quatro bases nitrogenadas: adenina, citosina, guanina e uracila (que substitui a timina do DNA). O RNA está presente tanto no núcleo quanto no citoplasma das células.
A estrutura helicoidal do DNA foi revelada em 1953 por Francis Crick e James Watson quando trabalhavam no laboratório Cavendish da Universidade de Cambridge. Em 1954, o físico George Gamow propôs que a especificação de um aminoácido (necessário para compor uma determinada proteína) estava contida numa sequência de três bases nitrogenadas adjacentes – o códon. Como há quatro bases nitrogenadas no DNA, esse tripleto (trinca) permitiria a codificação de 43=64 aminoácidos. Uma vez que os aminoácidos que sintetizam as proteínas são apenas 20, vários códons devem codificar o mesmo aminoácido (veja próxima secção).
Um gene é um segmento do DNA composto por uma determinada sequência de códons. Cada códon será uma instrução para agregar um determinado aminoácido quando da síntese de uma proteína. Tudo ocorre como num código de programação, daí seu nome – código genético. Estima-se que o DNA do ser humano possua de 20.000 a 25.000 genes, com um total de cerca de 3,2 bilhões de pares de nucleotídeos.
O código genético é o código da vida e é quase universal. Ele é semelhante em praticamente todos os organismos vivos, com pequenas variações encontradas no DNA mitocondrial.
Sintetizando uma proteína:
Foi na década de 1950 que os mecanismos bioquímicos para sintetizar uma proteína começaram a ser estudados. Até os dias de hoje, essa área de pesquisa foi laureada com mais de 20 prêmios Nobel. O processo de síntese de proteína é inacreditavelmente complexo, bonito e elegante. Vale a pena conhecê-lo.
Descrevemos aqui, de maneira sucinta, a síntese de proteínas em células eucariontes (que têm núcleo). Em células procariontes (sem núcleo, como as bactérias e vírus) o processo é semelhante, mas não é igual.
O processo da síntese proteica se divide, basicamente, em duas etapas: a transcrição e a tradução.
A transcrição
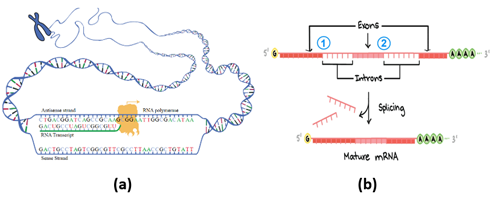
Figura 9 – (a) A transcrição de um gene do DNA gera um pré-RNAm. A enzima RNA polimerase II se acopla à fita template (antisense strand) e faz uma cópia da fita codificadora (sense strand) trocando a base timina pela uracila; (b) Recomposição (splicing) do pré-RNAm. Setores que não codificam (íntrons) são eliminados do RNA e as regiões codificadoras (éxons) são emendadas resultando no RNA mensageiro maduro (Crédito: domínio público)
Na transcrição do DNA, a enzima RNA polimerase se liga à região promotora do gene (composta, em geral, por cerca de 100 a 1000 pares de bases nitrogenadas) e começa a abrir (localmente) a fita dupla do DNA (expondo seus nucleotídeos) até encontrar uma região terminadora do gene.
Uma das fitas, chamada de codificadora, contém a sequência de códons da proteína, a outra, chamada de template, contém os anticódons (Figura 9a). Sobre a template, se liga a enzima RNA polimerase II que lê os anticódons e constrói, com as bases complementares, o precursor do RNA mensageiro – o pré-RNAm.
O pré-RNAm passa, então, por uma série de modificações que eliminam as regiões não codificadoras – os íntrons, e emendam todas as regiões que codificam – os éxons (Figura 9b). Ao final desse processo de recomposição (splicing), teremos o RNA mensageiro maduro.
Finalmente, o RNA mensageiro (RNAm) atravessa a membrana do núcleo e vai para o citoplasma onde se liga a um ribossomo.
A tradução
O ribossomo é um complexo de RNA e proteína. É uma macromolécula com duas subunidades: uma pequena – onde o RNA mensageiro (RNAm) se conecta e é decodificado e a outra grande – onde os aminoácidos específicos para uma determinada proteína são adicionados.
Para a decodificação, o ribossomo utiliza o círculo do código genético (Figura 10). O código de início (para qualquer proteína) é o códon AUG que codifica para o aminoácido metionina. Os três códigos de parada são: UGA, UAG e UAA que não codificam para nenhum aminoácido (com exceções da selenocisteína e da pirrolisina, leia legenda da Figura 10).
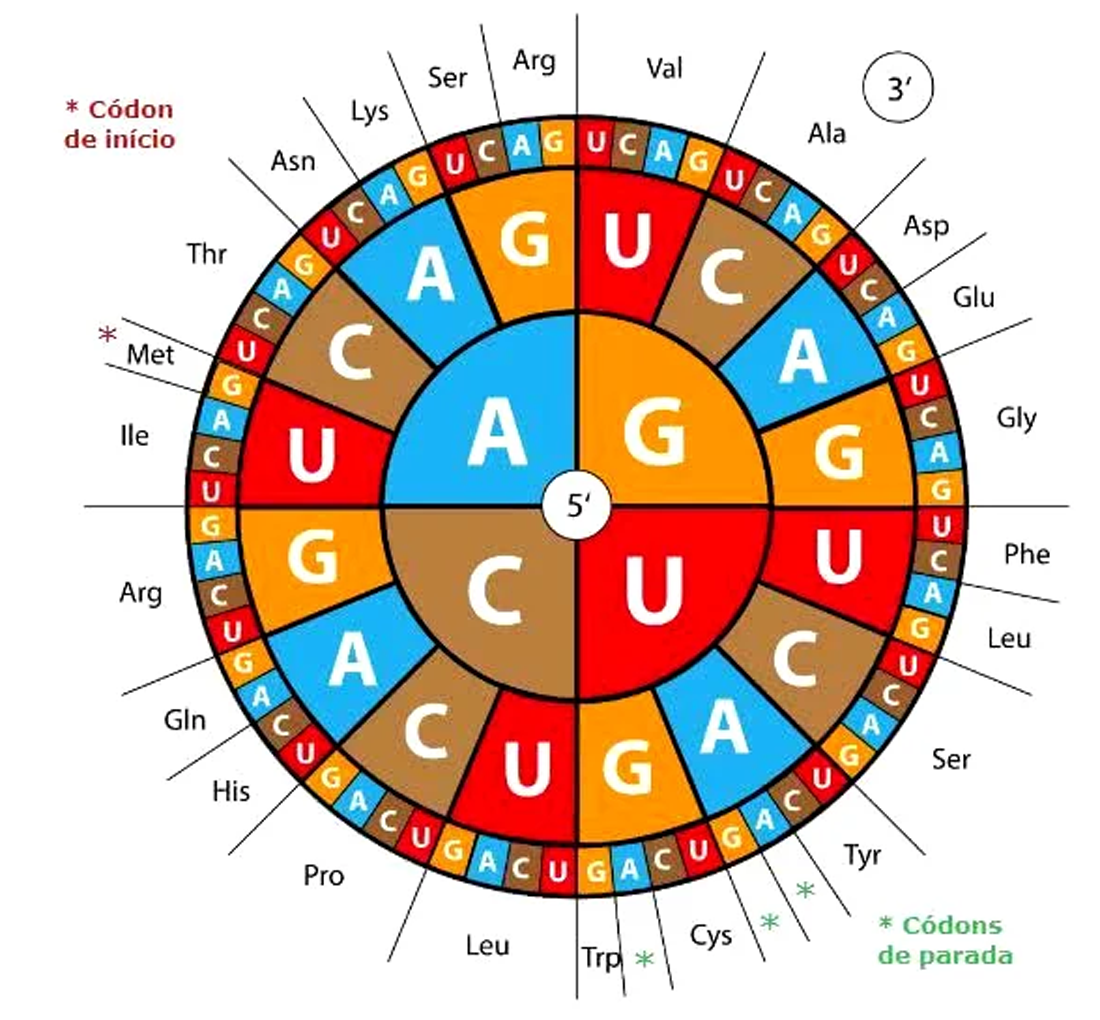
Figura 10 – O círculo do código genético. Os códons devem ser lidos do centro para fora. O aminoácido selenocisteína é incorporado à proteína se, no RNA mensageiro, o códon de parada UGA vem acompanhado do elemento de inserção SECIS ; já a pirrolisina utiliza o código de parada UAG e necessita da presença dos genes pyITSBCD. Há muitos códons codificando para o mesmo aminoácido. São códons sinônimos. Por exemplo, a serina é codificada por 6 códons: UCU, UCC, UCA, UCG, AGU e AGC (Crédito: domínio público)
O RNAm desliza ao longo do ribossomo que lê um códon de cada vez. O códon especifica (univocamente) o aminoácido que será incorporado à proteína em construção. O ribossomo convoca então, um RNA transportador (RNAt, Figura 12). Este RNAt tem o anticódon correspondente e carrega o aminoácido correto (graças à ação das enzimas aminoacil-tRNA sintetase). O RNAt se acopla ao RNAm e o aminoácido se liga à proteína.
Organismos genomicamente recodificados
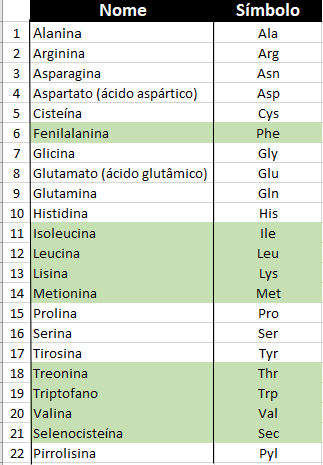
Figura 11 – Todas as milhões de proteínas existentes (em qualquer organismo vivo na Terra) são elaboradas a partir de meros 22 aminoácidos mostrados nesta tabela. Eles são chamados de aminoácidos canônicos (ou padrão). O 22º. aminoácido – a pirrolisina, não está presente no ser humano. Em verde, indicamos os aminoácidos essenciais (Crédito: R. N. Onody)
Durante 3,5 bilhões de anos a vida na Terra evoluiu e gerou os mais diversos e incríveis organismos. Mais inacreditável ainda é que a evolução tenha se utilizado de meros 20 aminoácidos para elaboração todas as proteínas necessárias! Isto está prestes a mudar pela ação do homem.
Se apenas 20 aminoácidos (22, se incluirmos a selenocisteína e a pirrolisina) bastaram para criar todos os seres vivos (em todas as épocas) imagine o que aconteceria de pudéssemos lançar mão dos 500 aminoácidos conhecidos?
Sabemos que existem cerca de 140 aminoácidos não canônicos presentes em proteínas naturais. Eles não fazem parte do código genético e se formam por modificações após a tradução da proteína. Exemplos: a carboxilação, isto é, a adição do grupo carboxila COOH ao glutamato resulta no ácido carboxiglutâmico (aminoácido presente em proteínas da cascata de coagulação); a hidroxilação, isto é, a adição do grupo hidroxila OH à prolina produz a hidroxiprolina, um aminoácido presente no colágeno. Temos, portanto, aminoácidos não canônicos, não codificados, mas, que estão naturalmente presentes nas proteínas dos seres vivos.
Com os enormes avanços das técnicas bioquímicas é possível inserir um aminoácido não canônico em novos medicamentos e obter ótimos resultados funcionais. Um exemplo recente, é o Ozempic que foi desenvolvido pela Novo Nordisk em 2012 (aprovado pela ANVISA em 2018) e é indicado para tratamento da diabetes tipo 2. Seu princípio ativo, a semaglutida, contém um aminoácido não canônico – o ácido 2-aminoisobutírico (AIB). O AIB é sintetizado em laboratório e incorporado à semaglutida por modificação do RNAt!
Essa engenharia utilizada em medicamentos poderia ser usada em seres vivos? Poderíamos modificar o código genético (construído arduamente pela natureza ao longo de bilhões de anos) de maneira a codificar para aminoácidos não canônicos?
Experimentos realizados em organismos com alterações apenas parciais do seu genoma resultaram em proteínas malformadas ou mesmo tóxicas. Consequentemente, concluiu-se que as modificações no código deveriam ser feitas em todo o genoma. O organismo daí resultante é chamado de Organismo Genomicamente Recodificado.
É importante não confundir os Organismos Genomicamente Recodificados com os Organismos Geneticamente Modificados. Estes existem há muito mais tempo e têm seu material genético alterado pela adição ou remoção de genes que muitas vezes (principalmente nas plantas) introduzem novas características como tamanho, sabor ou resistências a herbicidas. Uma das preocupações dessa tecnologia transgênica é de biossegurança, já que ela libera formas funcionais de DNA no meio ambiente.
Nos organismos genomicamente recodificados, entretanto, o objetivo é reescrever ou expandir o código genético! Expandir o código genético é um programa de pesquisa (de uma área chamada biologia sintética) que deve contemplar os seguintes pré-requisitos:
– Reatribuir um códon para que ele passe a codificar para aminoácidos não canônicos;
– Produzir um novo RNAt com o anticódon correspondente;
– Produzir uma nova enzima RNAt sintetase que carregue o novo RNAt com o aminoácido não canônico desejado.
Além disso, os biólogos sintéticos têm que garantir ainda que, durante a tradução, os processos sintéticos e endógenos (isto é, já existentes no organismo) não interfiram entre si, que sejam ortogonais! Qualquer mistura dos processos seria extremamente perigosa, com futuro imprevisível e consequências desconhecidas.
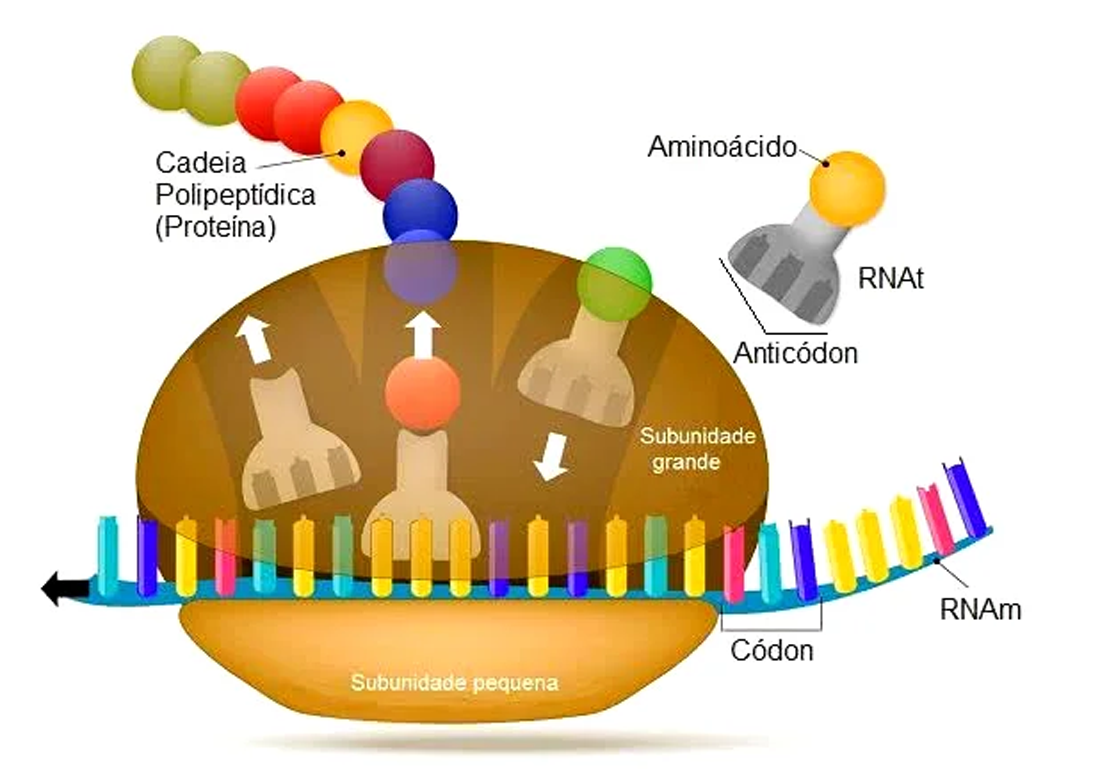
Figura 12 – A complexa e fascinante fase de tradução de uma proteína envolve o RNA mensageiro, o RNA transportador, o ribossomo e enzimas. Em eucariotos (procariotos), as proteínas crescem incorporando cerca de dois (quinze) aminoácidos por segundo. Quando a proteína está finalizada, o RNA mensageiro é degradado (Crédito: domínio público)
O primeiro organismo genomicamente recodificado foi a bactéria Escherichia Coli (E. Coli) em 2013. Identificada em 1885 por T. Escherich e presente no intestino humano, essa bactéria foi escolhida por ter um genoma relativamente pequeno (4.400 genes) que foi totalmente sequenciado em 1997.
Na E. Coli, a síntese de uma proteína termina quando, na presença e sob a ação do fator de liberação RF1 (Release Factor 1), o ribossomo encontra o códon de parada UAG. Esse códon é muito raro com somente 321 aparições no genoma da E. Coli.
Os pesquisadores converteram todos os códons UAG em UAA e deletaram os fatores RF1. O UAG deixou de significar um códon de parada para o E. Coli e, quando ele foi reintroduzido numa posição apropriada de um gene de interesse, ele pôde ser usado como códon codificador para aminoácidos não canônicos. Para que isso acontecesse, o E. Coli recebeu um novo RNAt e um novo aminoacil-tRNA-sintetase ortogonais aos endógenos. A bactéria E. Coli genomicamente recodificada estava agora pronta para testes e validação. E o novo organismo revelou ter adquirido vantagem imunológica.
Vírus vivem às custas de seu hospedeiro. Eles sequestram a máquina celular obrigando-a a produzir as proteínas que o vírus precisa. E, sim, as bactérias também são atacadas e mortas por vírus conhecidos como bacteriófagos. Testado o E. Coli genomicamente recodificado mostrou ter adquirido imunidade e resistência contra infecção dos vírus T4 e T7!
O processo descrito acima de recodificação de genoma de indivíduos procariotos também foi estendido para organismos eucariotos como Saccharomyces cerevisiae (a levedura do pão e da cerveja) e Caenorhabditis elegans (um nematoide).
Em outra vertente da pesquisa deseja-se utilizar a técnica de recodificação de genomas para proteger plantas de doenças virais. Vírus que atacam plantas – os fitovírus, causam grandes prejuízos na agricultura e podem infectar até mesmo plantas ornamentais. Estima-se que os fitovírus causem prejuízos de 60 bilhões de dólares por ano no mundo todo.
Por último e de maneira ainda mais radical, existem estudos que pretendem incorporar aminoácidos não canônicos às proteínas através de variantes do RNAt que decodificam para um quadrupleto, isto é, um códon de tradução com 4 bases!
A biologia sintética está apenas começando, mas seus avanços recentes apontam para um futuro promissor com o desenvolvimento de novas e potentes drogas abrangendo aminoácidos não canônicos. Além disso, estaremos abrindo novos caminhos para a evolução da vida na Terra com a criação de organismos genomicamente recodificados.
*Físico, Professor Sênior do IFSC – USP
e-mail: onody@ifsc.usp.br
Para acessar todo o conteúdo do site “Notícias de Ciência e Tecnologia” dirija a câmera do celular para o QR Code abaixo

Se você gostou, compartilhe o artigo nas redes sociais

(Agradecimento: ao Sr. Rui Sintra da Assessoria de Comunicação)
Assessoria de Comunicação – IFSC/USP